Hierarchická, síťová a objektová databáze
Historie hierarchické databáze, jejímž autorem je IBM, sahá až do šedesátých let, tedy ještě do dob sálových počítačů. Její princip je založen na stromové struktuře. Mezi hlavní nevýhody tohoto databázového systému ovšem patří, že podřízený záznam se může vztahovat pouze k jednomu nadřízenému záznamu.
Přesně tento nedostatek řeší síťová databáze. Ta již umožňuje, aby určitý záznam mohl mít více nadřazených záznamů. Síťová databáze byla hojně používána zejména v 80. letech. Později ale hierarchickou i síťovou databázi vytlačila na okraj relační databáze (SQL). Ta společně s nerelační databází (NoSQL) převažuje dodnes. Hierarchické a síťové databáze přesto zcela nevymizely a stále se využívají v případech, kdy je jejich jednoduchost z funkčních důvodů vítaná.
Za zmínku stojí také objektová databáze, která má specifickou povahu. Je totiž pevně spojena s objektově orientovaným programováním. Zatímco relační databáze bývají většinou striktně odděleny od aplikací, ty objektové úzce souvisí s konkrétním programovacím jazykem jako třeba Perl, Ruby nebo Python. Namísto tabulek, které jsou typické pro relační databázi, pracuje objektová databáze přímo s objekty, na něž jsou navázány jejich vlastnosti a instance.
Relační databáze
Nejpoužívanějším typem je v současnosti relační databáze. Jak už název napovídá, jejím základem jsou tzv. relace, což jsou vlastně databázové tabulky. Ty se skládají ze sloupců (atributů) a z řádků (záznamů). Pro názornější vysvětlení využijeme obrázek níže.

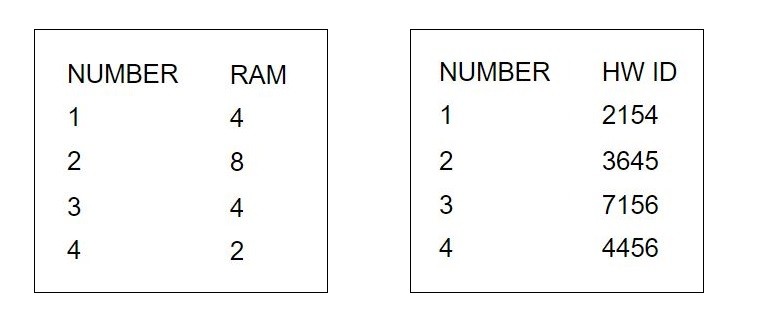
Příklad jednoduché relace SQL databáze
Relací je zde „RAM SIZE”, tedy celá tabulka. Atributy jsou celkem tři: „NUMBER”, „HW ID” a „RAM”. Záznamy máme v relaci čtyři. Jednotlivé atributy pak mohou plnit například funkci kandidátního, primárního, alternativního nebo cizího klíče. V případě kandidátního klíče se jedná o atributy, jež jednoznačně určují, o jaký záznam se jedná. V relaci „RAM SIZE” jsou tak kandidátními klíči atributy „NUMBER” a “HW ID”.
Všechny atributy, které jsou označovány jako kandidátní klíče, se teoreticky mohou stát primárním klíčem. Ty, které se jím nestanou, se pak nazývají alternativní klíče. Primární klíč musí, kromě své unikátnosti, vždy obsahovat nenulovou hodnotu a měl by být neměnný. Pokud neexistuje přirozený primární klíč (unikátní identifikátor, například pořadí běžců v cíli), použije se uměle vytvořený identifikátor. Ten se automaticky přiřadí každému novému záznamu. V relaci výše by tomu odpovídal sloupec „NUMBER”.
Relační databáze se tvoří pomocí jazyka SQL (Structured Query Language). Díky strukturovanosti a vysoké konzistentnosti je možné záznamy v tabulce snadno filtrovat, třídit a provádět s nimi výpočty. Jednotlivé relace (tabulky) lze provázat i mezi sebou. Právě k tomu slouží tzv. cizí klíč, jenž se shoduje s primárním klíčem jiné relace. V praxi se v různých systémech propojují například záznamy o zákaznících, objednávkách a produktech, které jsou uvedeny v oddělených relacích.
Schéma provázání různých relací, které spolu úzce souvisí. Zdroj: Reaserchgate.net
Mezi konkrétní SQL databázové systémy patří třeba MySQL, Oracle, Microsoft SQL nebo MariaDB, jež vznikla jako alternativní větev MySQL. Důvodem byly obavy vývojářů o zachování licence svobodného softwaru GNU GPL po odkoupení MySQL firmou Oracle. Podle různých zdrojů je v současnosti MariaDB v mnohých vlastnostech lepší než MySQL. Zasloužila se o to zejména široká komunita open source vývojářů.
Nerelační databáze
NoSQL databáze, neboli nerelační databáze, se od té relační zásadně liší. Neukládá totiž data v pevně definovaných tabulkách. Tento datový model je tak velmi flexibilní a dovoluje kombinovat odlišné struktury dat bez nutnosti zasahovat do schématu databáze. Název NoSQL však může být trochu zavádějící, protože nerelační databáze umí pracovat rovněž s SQL dotazy. Přesnější název by tak byl „NotOnlySQL” nebo „Nejen relační databáze”.
Existuje několik podtypů NoSQL databáze, které se odlišují tím, jak pracují s jednotlivými záznamy. Tou nejjednodušší variantou je „Key-value” databáze. Ta přiděluje každé hodnotě při ukládání unikátní klíč. Hodnota může mít podobu čísla, řetězce nebo klidně odkazu na další pár „klíč–hodnota”. Na rozdíl od relační databáze zde není předdefinovaná přesná struktura, což umožňuje vysokou flexibilitu a snadné propojování záznamů.
Dalším podtypem je „Document-oriented” databáze, jež je založená na ukládání dat v dokumentu, a to nejčastěji ve formátu JSON, BSON nebo XML. Samotné dokumenty opět obsahují klíč a hodnotu. Výhodou oproti relačnímu modelu je například možnost skladovat záznamy s odlišnými parametry v jednom dokumentu.
V příkladu níže byl třeba do záznamu vpravo přidán klíč „Rainbow”. V relační databázi by se musela změnit celá tabulka, v NoSQL to ale není problém. Klidně by do ní bylo možné přidat záznam, který se týká zcela něčeho jiného než počasí a nebylo by nutné měnit schéma celé databáze.
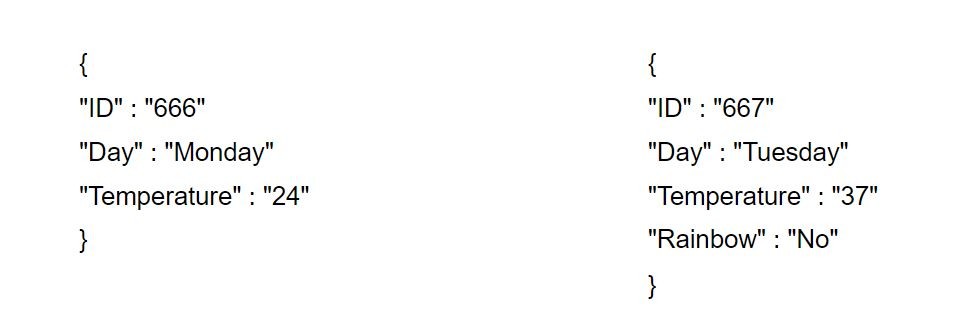 Dva záznamy z jednoho JSON dokumentu mohou mít rozdílné klíče, respektive parametry, aniž by se muselo měnit schéma celé databáze.
Dva záznamy z jednoho JSON dokumentu mohou mít rozdílné klíče, respektive parametry, aniž by se muselo měnit schéma celé databáze.
Podtyp „Wide-column store” značně připomíná relační databázi. Je ale založen pouze na sloupcích, nikoliv na sloupcích a řádcích. Příklad naší relační tabulky přepsaný do tohoto typu databáze by vypadal jako dvě tabulky propojené klíčem ve sloupci „NUMBER”, viz obrázek níže.
 Výhodou podtypu wide-column store je, že lze snadno přidávat další parametry. S klíčem je totiž vždy spojena jen jedna hodnota, což je hlavní rozdíl oproti relační databázi.
Výhodou podtypu wide-column store je, že lze snadno přidávat další parametry. S klíčem je totiž vždy spojena jen jedna hodnota, což je hlavní rozdíl oproti relační databázi.
Poslední podtyp NoSQL databáze, který zmíníme, je „Graph database”, jenž je založen na dvou elementech – uzlech (nodes) a vztazích mezi nimi (edges). Uzly představují konkrétní záznamy, zatímco vztahy pomocí vlastností definují, jak jsou tyto záznamy mezi sebou propojené. Jedná se o relativně specifický model, jenž není až tak často používaný.
Systémů pro nerelační databáze existuje mnoho. Mezi ty nejpoužívanější patří například MongoDB, Elasticsearch, Apache Cassandra, Amazone Neptune nebo Redis.
Výhody a nevýhody obou databází
Významným rozdílem mezi relační a nerelační databází je jejich škálovatelnost, respektive možnost upgradu hardwarových zdrojů za účelem zvýšení výkonu databáze. U obou typů databázových systému lze škálovat vertikálně. Tedy přidávat například RAM, kapacitu pevného disku nebo počet jader procesoru v rámci jednoho stroje.
U nerelační databáze lze však snadno škálovat i horizontálně, což v praxi znamená přidávání dalších samostatných serverů. V takovém případě se záznamy doplní o tzv. „keyspace”, který prozrazuje, na jakém serveru se daná entita vyskytuje. To umožňuje velmi flexibilně přidávat další zdroje, například společnost Apple používá pro svou nerelační databází přes 75 tisíc serverů.
V případě relační databáze je sice horizontální škálování také možné, ale jedná se o dosti komplikovaný proces. Proto byste měli předem vědět, jakou bude mít databáze zhruba velikost i co vše, a jak často, se do ní bude zapisovat nebo z ní číst. Její architektura se totiž navrhuje předem a měnit ji za provozu je často problematické. Pokud se zvolí nerelační databáze, dá se mnoho takových věcí řešit za běhu podle potřeby.
Díky možnosti vložit ke každému záznamu libovolný počet i typ parametrů je nerelační databáze, jak už bylo zmíněno, mnohem flexibilnější. Není totiž vázána na pevné schéma atributů a řádků jako v případě tabulek.
Relační databáze je naopak, vzhledem ke svému neměnnému schématu, velice konzistentní a vyznačuje se vysokou integritou dat. To se hodí pro případy, kdy záznamy obsahují vždy stejný, nebo alespoň podobný, typ a počet hodnot, protože se skladují v rámci pevně daného schématu.
Pro jakou databázi se rozhodnout?
Vhodné použití relační nebo nerelační databáze úzce souvisí s jejich vlastnostmi. Do volby té pravé vstupuje celá řada parametrů a nelze tak jednoduše říct, že třeba pro mobilní aplikaci je lepší nerelační databáze. Nejdřív se totiž musí specifikovat, kolik lidí bude aplikaci používat, jaký typ entit se bude ukládat, jestli se povaha záznamů nebude časem lišit a spousta dalších detailů.
Obecně platí, že pokud se váš projekt organicky vyvíjí a vy netušíte kolik dat a v jaké podobě budete skladovat, je na místě sáhnout po nerelační databázi, která vás v budoucnu nebude svazovat pevným schématem. Třeba při sběru analytických dat z různých, a časem přibývajících, zdrojů je nerelační databáze často ideální volba.
Naopak v situaci, kdy se ukládají neměnné záznamy s přísnou strukturou a kdy lze odhadnout potřebnou architekturu databáze, bude komfortnější zvolit relační databázi. Příkladem může být ukládání transakčních dat nebo tvorba dynamického e-shopu s podobně strukturovanými položkami.
Do rozhodování samozřejmě promlouvají také náklady za hardwarové zdroje, jejich optimalizaci a administraci celého řešení. Jedná se v podstatě o samostatnou IT disciplínu, kterou se mnohdy vyplatí outsourcovat specializované firmě. V Masteru například nabízíme komplexní službu Database as a Service (DBaaS) spravovanou našimi odborníky na databáze.
Služba běží na výkonném hardware DELL EMC a díky technologiím Kubernetes a Docker je velmi dobře škálovatelná a izolovaná. Load balancer zase směřuje dotazy k jednotlivým instancím a zajišťuje dostupnost služby i v případě výpadku některého z uzlů. Platforma je určená zejména pro MySQL a MariaDB databáze.

